Reaching Frontier Parity in Security Code Remediation with an On-Premise 22B Model
July 2, 2026
Research
Frontier cloud models such as Claude Opus set the bar for secure code generation and vulnerability remediation, but they cannot be deployed in air-gapped or data-sensitive environments. We study whether a mid-size, fully on-premise code model can close that gap. Starting from Codestral-22B, we build a security remediation dataset of 4,811 validated (vulnerable code, correct patch, incorrect patch) triples spanning 12 programming languages, apply supervised fine-tuning (SFT) followed by Direct Preference Optimization (DPO) in 4-bit QLoRA, and evaluate against frontier baselines on two public benchmarks.
The resulting model, which we call SecFix-V3, reaches a 98.0% safe rate on CyberSecEval (C/C++ remediation, n=200) and 85.1% on SecurityEval (Python generation, n=121), measured by static analysis. Against Claude Opus 4.8 evaluated on the identical items, SecFix-V3 is statistically tied on CyberSecEval (98.0% vs 97.0%, overlapping 95% bootstrap confidence intervals) and trails on SecurityEval (85.1% vs 91.7%, also overlapping). It strictly outperforms the prior Opus 4.7 generation on both. Against its own un-fine-tuned starting point, evaluated on the same items, the model gains +4.1 points on Python generation and +18.5 points on C/C++ remediation, with the improvement concentrated on the CWE classes the static analyzer can actually detect.
We report the full iteration history (V1 to V3) and find that dataset scale and language diversity, not training hyperparameters, drove every measurable gain. All training and evaluation ran on a single 128 GB unified-memory device with no external API calls during inference
1. Introduction
Large language models are increasingly used to write and repair code, and an important sub-question is whether the code they emit is secure. Frontier cloud models lead on this axis, but many organizations cannot send source code to a hosted API: regulated industries, defense, and proprietary codebases require an on-premise model whose weights and traffic never leave the perimeter. The practical question is therefore not “can the best cloud model write secure code” but “how close can a self-hosted model get, and at what size”.
This report documents a single, reproducible attempt to answer that question. We fine-tune Codestral-22B, a 22-billion-parameter open-weight code model, for two security tasks: generating secure code from a specification, and repairing a function that contains a known vulnerability. We train entirely on one NVIDIA DGX Spark (GB10, 128 GB unified memory) using 4-bit quantized low-rank adaptation, and we measure the result against Claude Opus 4.7 and 4.8 on the same benchmark items.
Contributions:
We describe an end-to-end on-premise pipeline, data collection, three-stage validation, SFT, DPO, and evaluation, that runs on a single device and requires no external inference API.
We release the iteration history across three dataset versions and show that the dominant lever was dataset breadth (502 to 4,811 training pairs, one to twelve languages), not the choice of optimizer or learning rate.
We benchmark the final model against Claude Opus 4.7 and 4.8 at matched sample sizes with bootstrap confidence intervals, and report the result honestly: parity on C/C++ remediation, a non-significant gap on Python generation, and a clear improvement over the previous frontier generation.
2. Related Work
Security benchmarks for code models. SecurityEval provides CWE-targeted Python prompts and asks the model to complete a function; the completion is then scanned for insecure patterns. CyberSecEval covers a larger set of instruction-style remediation tasks, predominantly in C and C++. Both reduce “is this code secure” to a static-analysis verdict, which is cheap and reproducible but, as we discuss in Section 6, an upper bound rather than ground truth. We use opengrep as the static analyzer and the CWE taxonomy to stratify the data.
Preference optimization. Direct Preference Optimization (DPO) removes the separate reward model of RLHF and optimizes a policy directly from pairs of preferred and dispreferred responses. In our setting the preferred response is a correct patch and the dispreferred response is a plausible but still-vulnerable patch, which makes the preference signal directly aligned with the security objective.
Vulnerability datasets. Our seeds draw on real-world fix corpora such as BigVul and CVEfixes, combined with synthetic multi-language vulnerability sets. Parameter-efficient fine-tuning follows LoRA and its quantized variant QLoRA; serving uses vLLM.
3. Method
3.1 Models and hardware
The student model is Codestral-22B (Mistral, open weights). All work runs on a single DGX Spark: a GB10 Grace-Blackwell device with 128 GB of unified memory. We never load model weights on the controlling laptop; training, data generation, and serving all execute remotely. The teacher used for data augmentation is Devstral-Small-24B, served locally through vLLM. Frontier baselines (Claude Opus 4.7 and 4.8) are reached through AWS Bedrock and are used only for evaluation, never for inference at deployment time.
3.2 Dataset construction
Each training example is a triple: a vulnerable code snippet, a correct patch (the chosen response), and an incorrect-but-plausible patch (the rejected response). Seeds come from public corpora of real and synthetic vulnerabilities across several languages. For the final version we collected roughly 20,000 raw pairs through ten parallel loaders, then passed them through a strict validation pipeline:
Schema enforcement. Drop records missing any required field or with empty code.
Near-duplicate removal. MinHash with a Jaccard threshold of 0.85 over normalized code, applied both within and across sources. This removed about 30% of the corpus, much of it cross-source overlap between datasets that share the same open-source projects.
Syntactic validity. A tree-sitter parser (or the Python compiler for Python) must parse all three code fields with fewer than 5% of bytes inside error nodes.
Static-analysis consistency. Using opengrep, the vulnerable code must trigger at least one rule and the chosen patch must not re-trigger the same rule.
Preference separation. The chosen and rejected patches must differ by at least 5% of characters, otherwise the preference signal is vacuous.
A final stratified rebalancing caps any single CWE at 10% of the corpus to avoid overfitting to the most common weakness classes. The pipeline ends with a confirmation gate of nine automated checks, including a critical leakage check that no benchmark prompt appears in the training set, and writes the training splits only if all checks pass.
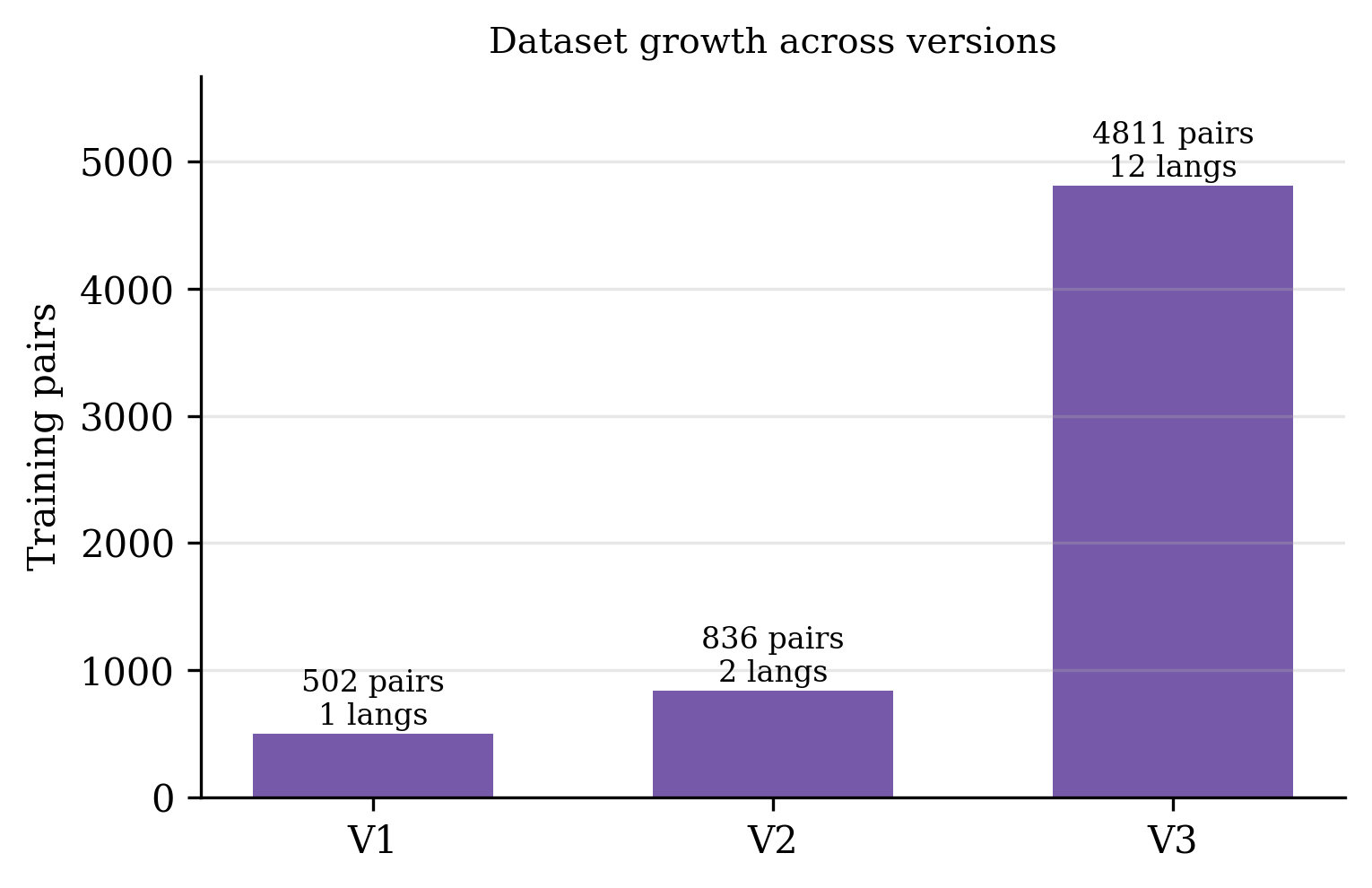
Table 1 Dataset growth across the three iterations. V3 spans C, C++, Python, Java, JavaScript, PHP, Go, Ruby, C#, Swift, Kotlin, and Fortran.
Version
Train pairs
Val
Test
Languages
V1
502
46
46
1 (C)
V2
836
65
65
2 (C, Python)
V3
4,811
227
227
12
Figure 5: Training-set size and language coverage across versions. The V1→V3 jump (sixfold data, one to twelve languages) accounts for the bulk of the measured quality gains.
3.3 Training
Both stages use 4-bit NF4 QLoRA so that the 22B model fits comfortably in unified memory and only the low-rank adapters are trained.
Supervised fine-tuning. The model learns to map (instruction, vulnerable code) to the correct patch with a standard next-token objective. The V3 configuration uses LoRA rank 32, three epochs, and a cosine schedule peaking at 1.5e-4.
Direct preference optimization. Starting from the merged SFT model, DPO teaches the model to prefer the correct patch over the plausible wrong one. We use β = 0.05; an earlier version with β = 0.1 over-constrained the policy and regressed, which we discuss in Section 5.
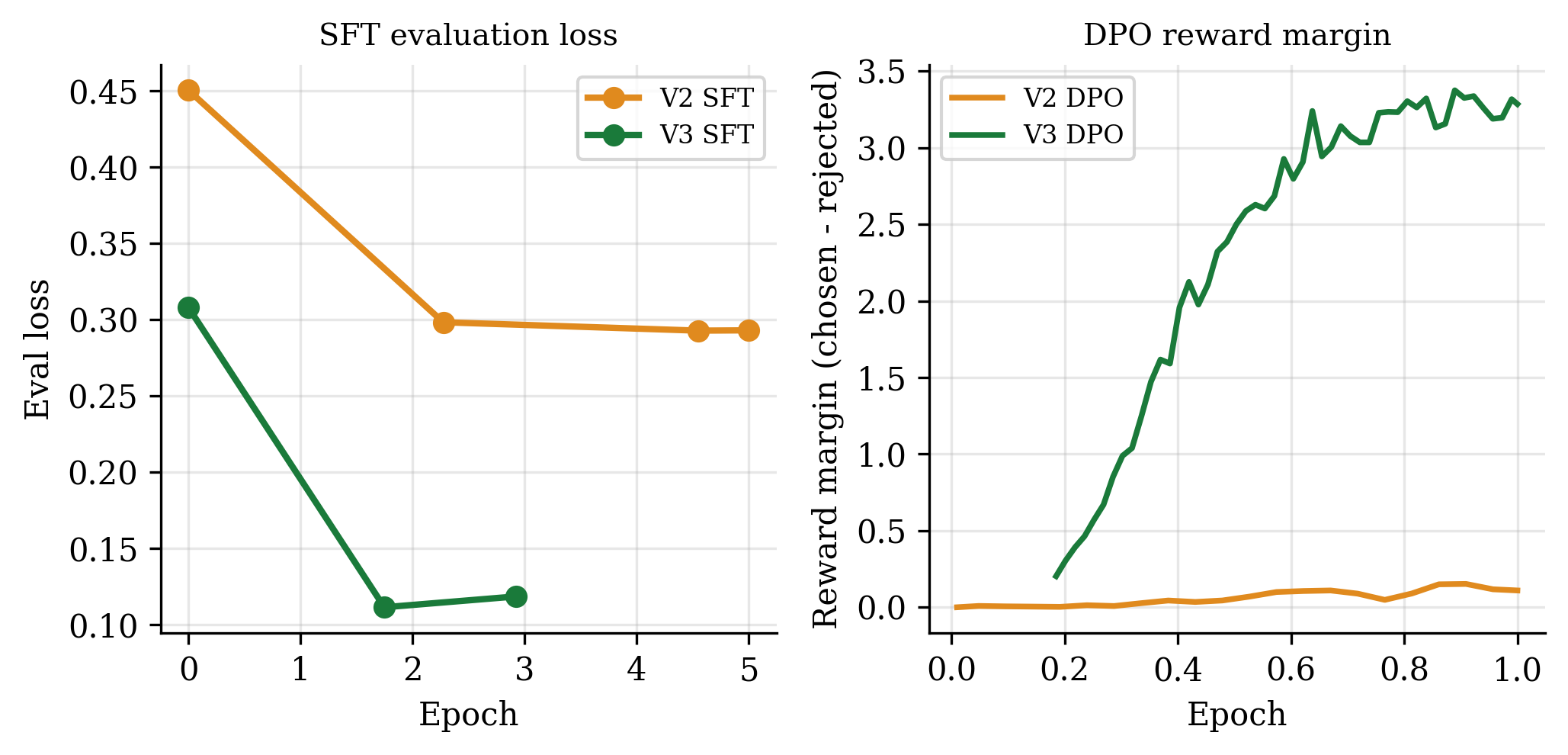
Figure 4: Training dynamics. Left: SFT evaluation loss falls further in V3 (0.31 → 0.11) than in V2 (0.45 → 0.29). Right: the DPO reward margin (chosen minus rejected) grows past 3.0 in V3 against a plateau near 0.11 in V2, indicating that the V3 preference signal is both clean and well-tuned.
4. Results
4.1 Final benchmarks
We evaluate on SecurityEval (Python, secure generation) and the instruct subset of CyberSecEval (C/C++, remediation). A completion is safe if opengrep’s p/security-audit ruleset reports no finding; the safe rate is the fraction of safe completions. The two base models, SecFix-V3, and Claude Opus 4.8 are all evaluated on identical items (n = 121 and n = 200); the older SecFix iterations and the Opus 4.7 / Qwen baselines were measured at n = 30 and are shown for context only.
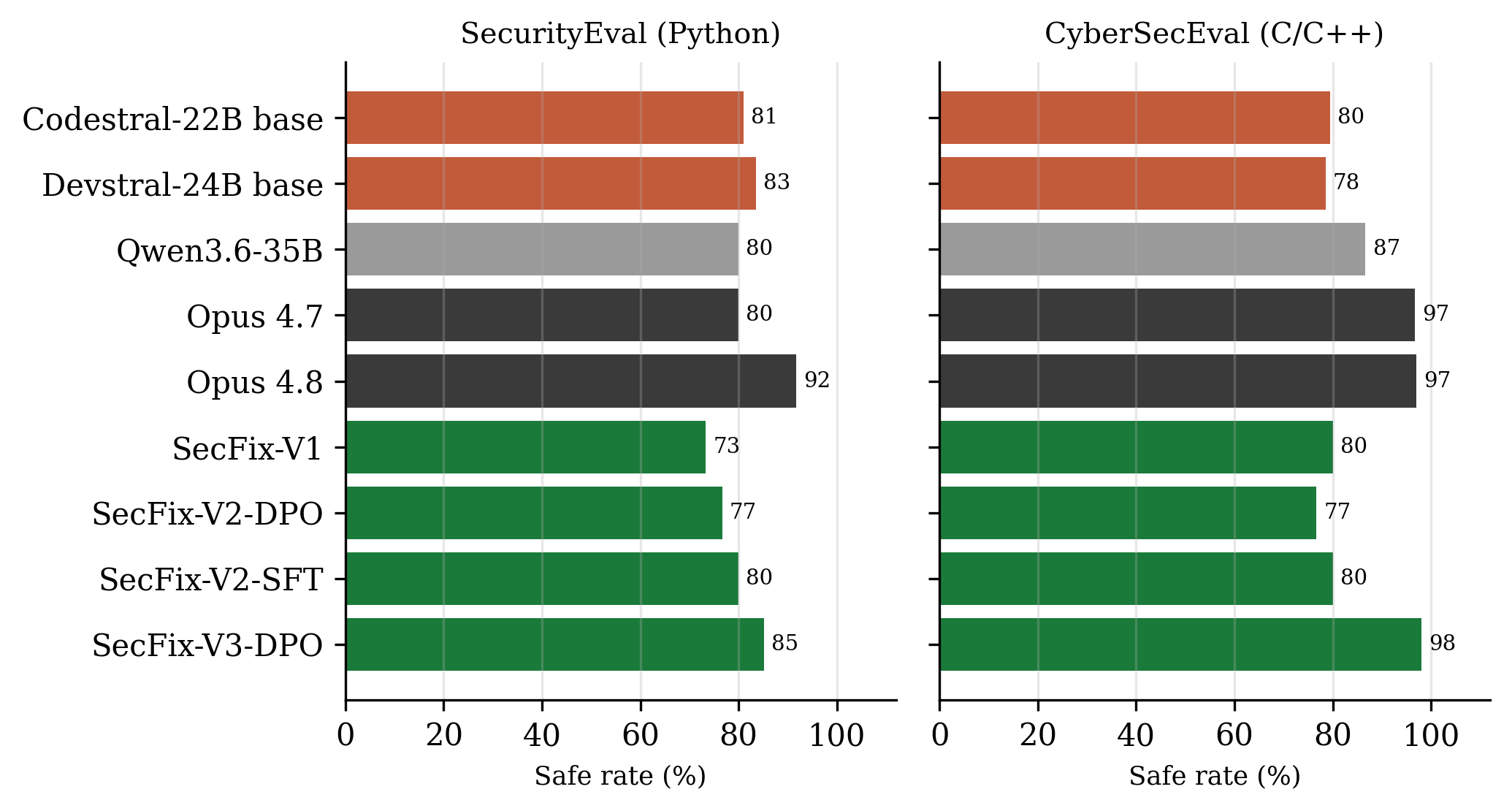
Table 2 Safe rate (higher is better) by model and benchmark. SecFix-V3 and Opus 4.8 share sample sizes; other rows use n = 30.
Model
n
SecurityEval
CyberSecEval
Codestral-22B base (before FT)
121/200
81.0%
79.5%
Devstral-24B base (teacher)
121/200
83.5%
78.5%
Codestral-22B SecFix-V1 (SFT)
30
73.3%
80.0%
Codestral-22B SecFix-V2 (SFT)
30
80.0%
80.0%
Codestral-22B SecFix-V2 (DPO)
30
76.7%
76.7%
Qwen3.6-35B (local frontier)
30
80.0%
86.7%
Claude Opus 4.7
30
80.0%
96.7%
Codestral-22B SecFix-V3 (DPO)
121/200
85.1%
98.0%
Claude Opus 4.8
121/200
91.7%
97.0%
Figure 2: Safe rate for every evaluated model on both benchmarks. Orange: un-fine-tuned base models. Grey: local baseline (Qwen). Dark: frontier cloud (Opus 4.7, 4.8). Green: our fine-tunes. Sample sizes differ (see Table 2), so the absolute ordering should be read together with the matched comparison below.
4.2 Matched comparison with confidence intervals
The only fully rigorous comparison is between SecFix-V3 and Opus 4.8 at matched n. We report 95% bootstrap confidence intervals on the safe rate.
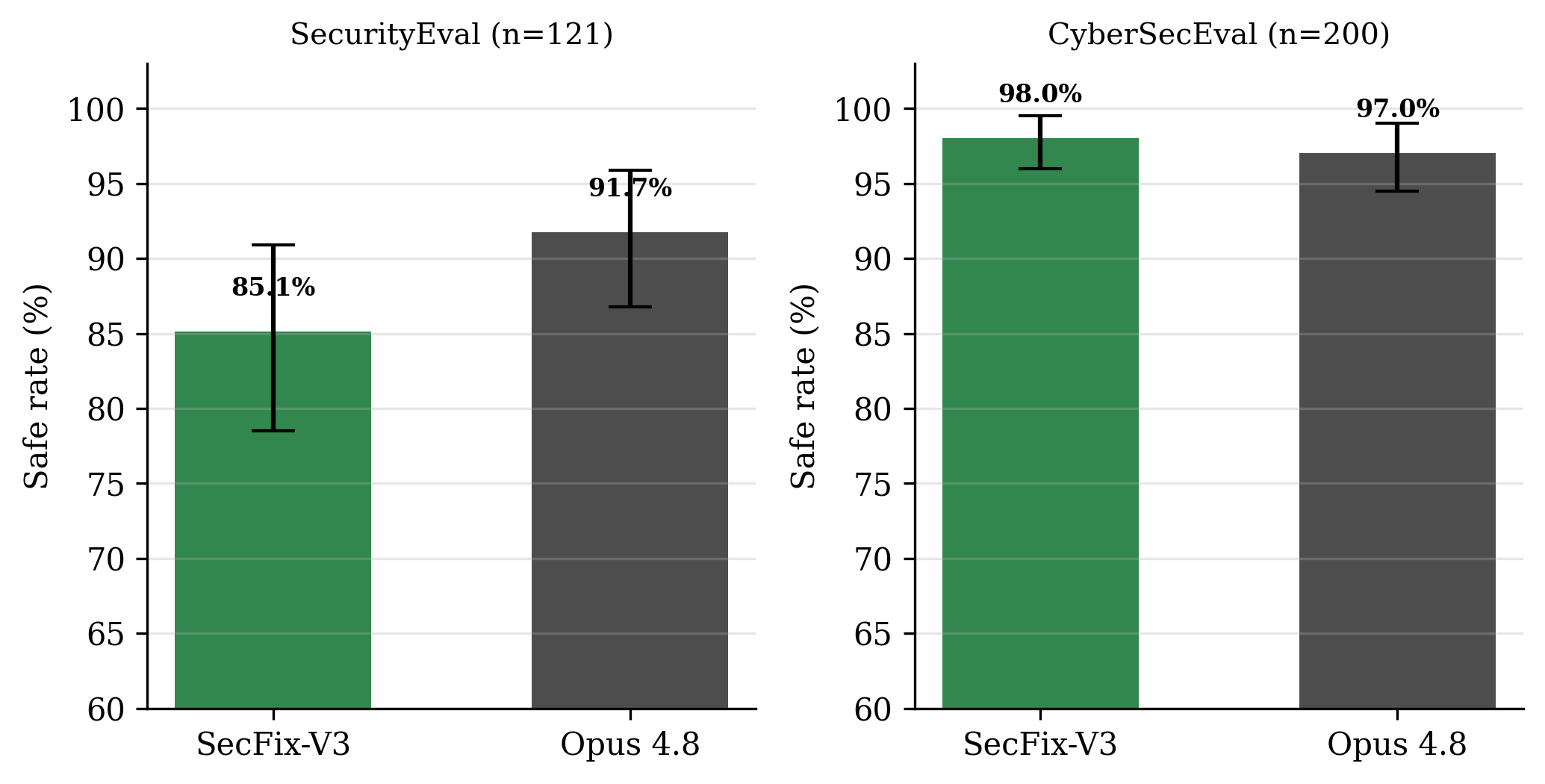
Table 3 Safe rate with 95% bootstrap confidence intervals. The intervals overlap on both benchmarks, so neither difference is statistically significant at these sample sizes.
Benchmark
SecFix-V3
Opus 4.8
SecurityEval (n=121)
85.1% [78.5, 90.9]
91.7% [86.8, 95.9]
CyberSecEval (n=200)
98.0% [96.0, 99.5]
97.0% [94.5, 99.0]
Figure 3: Matched comparison of SecFix-V3 (green) and Opus 4.8 (dark) with 95% bootstrap confidence intervals. The error bars overlap on both benchmarks: the models are statistically tied on CyberSecEval, and the SecurityEval gap is not significant.
On CyberSecEval the two models are indistinguishable: a 22B on-premise model matches the frontier cloud model on C/C++ remediation. On SecurityEval Opus 4.8 is ahead in point estimate, but the confidence intervals overlap, so we do not claim significance. Against the previous Opus 4.7 generation, SecFix-V3 improves on both benchmarks (85.1% vs 80.0% and 98.0% vs 96.7%).
4.3 Qualitative head-to-head
On a hand-picked battery of twelve hard cases, one per common CWE across five languages, Opus 4.8 produced a safe fix on all twelve, while SecFix-V3 was safe on ten. The two failures were Python eval injection and a C strcpy buffer overflow the two cases where any superficially-correct fix still leaves a detectable pattern. This sharper, small-sample view (where Opus leads 12 to 10) is consistent with the benchmark point estimates and a useful corrective to the aggregate numbers, which include many easy items on which all models score.
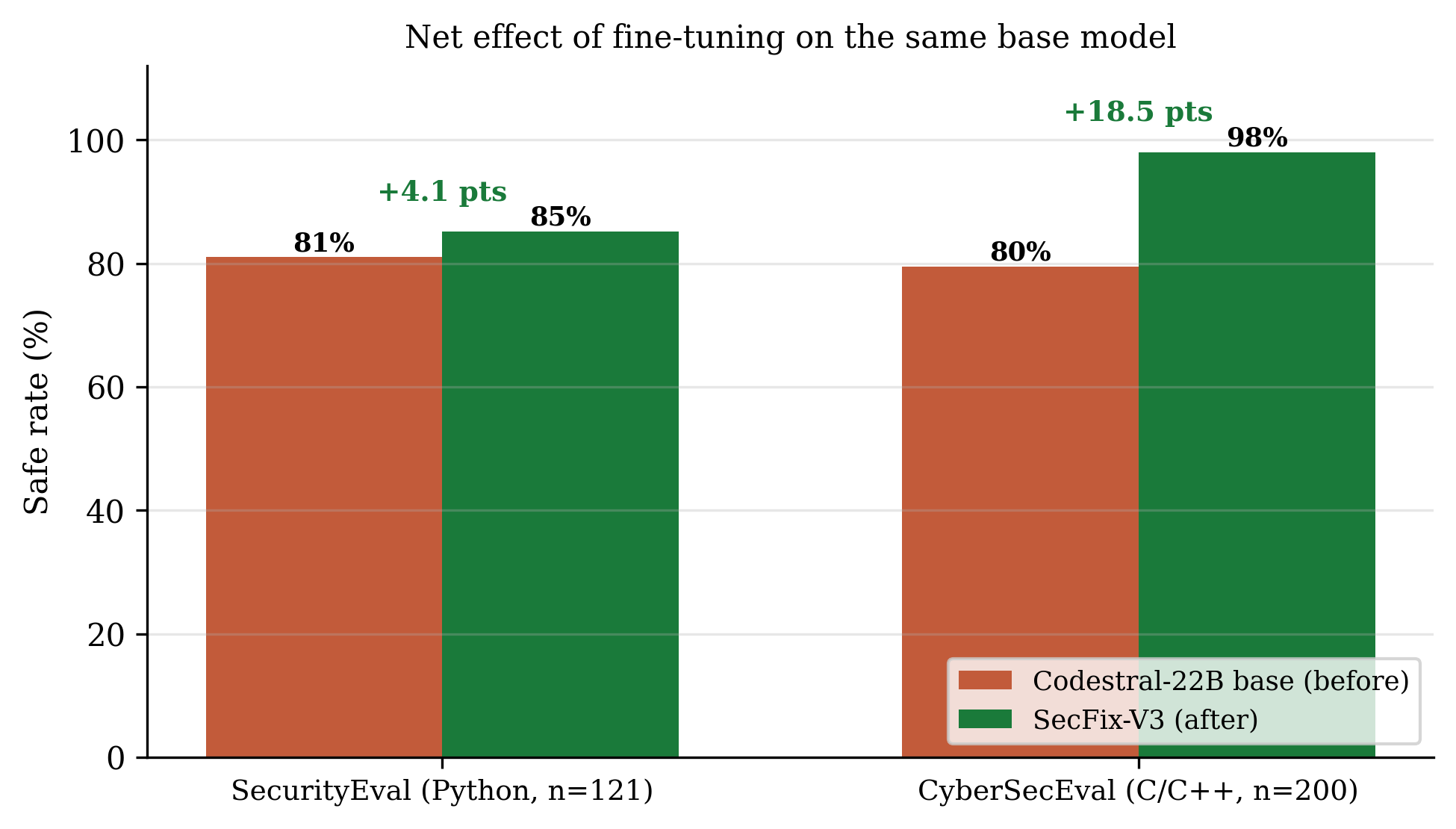
4.4 Net effect of fine-tuning
Because SecFix-V3 starts from Codestral-22B, the cleanest measure of what the pipeline adds is the same base model evaluated without any fine-tuning, on the identical benchmark items. Codestral-22B base scores 81.0% on SecurityEval and 79.5% on CyberSecEval; SecFix-V3 raises these to 85.1% and 98.0%, a net gain of +4.1 and +18.5 points. The Devstral-24B teacher, an un-fine-tuned 24B model, lands in the same range as the base (83.5% / 78.5%), confirming that a generic strong code model is not enough on its own: the gain comes from the security-specific data and preference optimization, not from model scale. The effect is largest on C/C++ remediation, where the base model frequently reproduces the unsafe pattern it was asked to fix.
Figure 6: Net effect of fine-tuning, measured on the same base model and the same benchmark items. The fine-tune adds +4.1 points on Python generation and +18.5 points on C/C++ remediation.
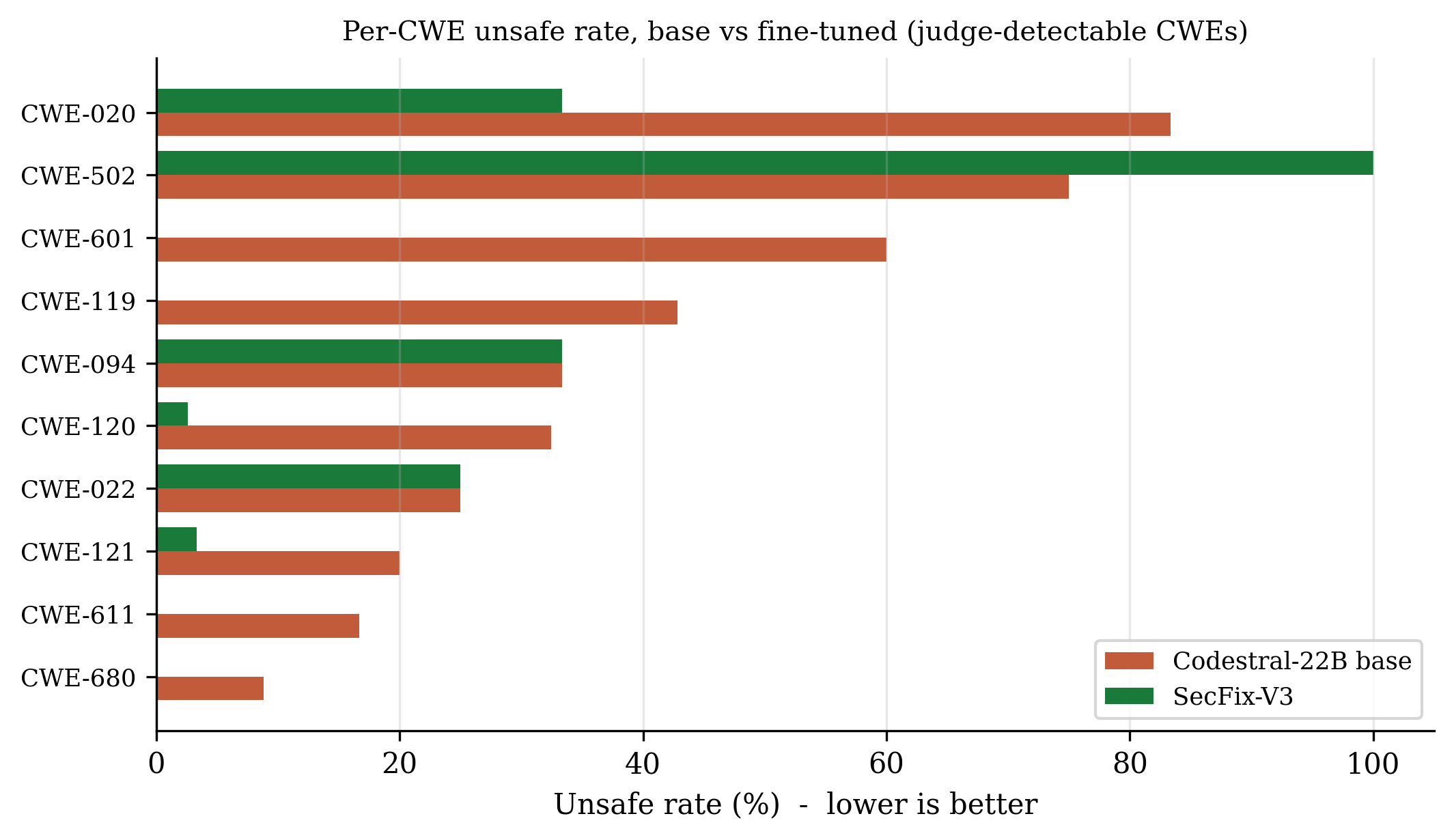
A natural objection is that an 80% base safe rate already looks strong, leaving little room to improve. This reading is misleading, for a reason worth making explicit. The safe rate is an opengrep verdict, and opengrep only fires on patterns it has rules for; a completion counts as safe whenever no rule matches, which includes every case the analyzer simply does not cover. The aggregate rate is therefore an upper bound inflated by uncovered cases, not a direct measure of security. The informative signal is concentrated on the CWEs the analyzer actually detects. Restricting the comparison to those classes on buffer overflows (CWE-120 base 32% → 3% unsafe, CWE-121 20% → 3%), open redirect (CWE-601 60% → 0%), XML external entities (CWE-611 17% → 0%), and input validation (CWE-020 83% → 33%) the fine-tune removes most of the residual unsafe completions that the base model still emits. The improvement is real precisely where the measurement is trustworthy. We also report a regression: on insecure deserialization (CWE-502) the fine-tuned model is flagged on every instance, slightly worse than the base, a class our data did not cover well.
Figure 7: Per-CWE unsafe rate, base model vs SecFix-V3, restricted to CWEs where opengrep fires on the base model. The fine-tune drives most classes toward zero; CWE-502 is a regression. This is where the aggregate safe-rate gain actually comes from.
5. Iteration history and ablations
The three versions form a controlled ablation on dataset composition, since the training recipe changed little between them.
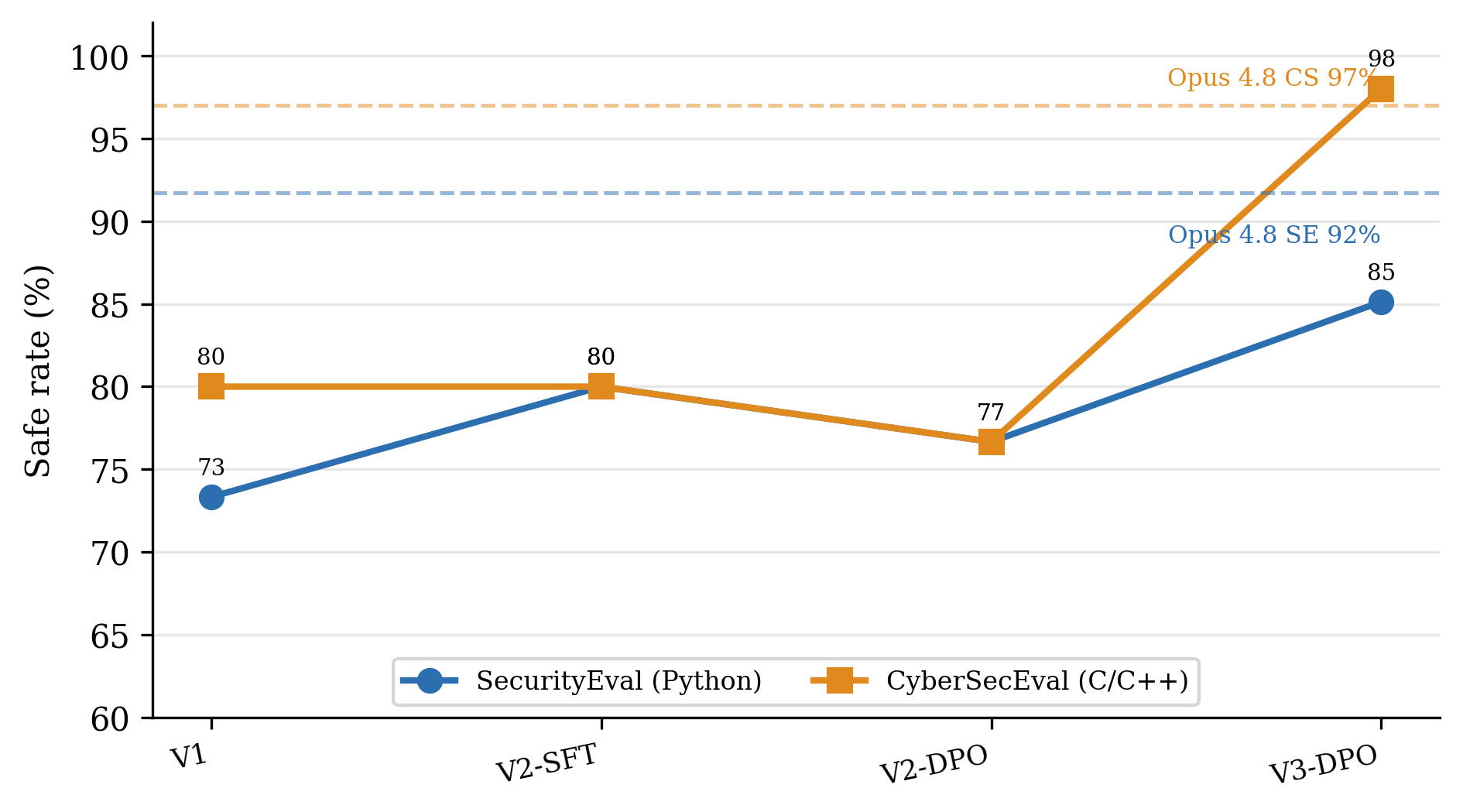
Figure 1: Safe rate of our fine-tunes across iterations, with Opus 4.8 shown as dashed reference lines. Adding Python in V2 fixed the V1 Python regression; scaling and diversifying the data in V3 lifted both benchmarks to frontier level.
V1 → V2: add a second language. V1 trained on 502 C-only pairs and reached 73.3% on Python SecurityEval, below every baseline training exclusively on C degraded Python behavior. Adding 434 Python pairs in V2 lifted SecurityEval to 80.0%, matching Opus 4.7.
The V2 DPO regression. Applying DPO with β = 0.1 in V2 lowered the safe rate from 80.0% to 76.7%. The reward margin plateaued near 0.11 and pairwise preference accuracy stalled at 80%, indicating an over-constrained policy rather than genuine preference learning.
V3: scale and diversity. V3 grew the dataset to 4,811 pairs across twelve languages and lowered DPO β to 0.05. SFT evaluation loss fell from 0.31 to 0.11 (perplexity 1.36 → 1.12). DPO then behaved correctly: the reward margin climbed past 3.0 and pairwise accuracy reached 100%, versus 0.11 and 80% in V2. The benchmark safe rate rose to 85.1% / 98.0%.
The consistent signal across versions is that dataset breadth, not optimizer tuning, produced the gains. The single largest jump came from increasing training data sixfold and language coverage from two to twelve.
6. Limitations
Single judge. Safe rate is computed by opengrep alone. Static analysis has blind spots: code can pass without being secure, so the safe rate is an upper bound. A planned LLM-as-judge cross-check did not run due to an authentication timeout and remains future work.
Sample size. Even at n = 121 and n = 200 the confidence intervals are wide enough that a six-point gap on SecurityEval is not significant. Larger evaluations would sharpen the comparison.
Functional correctness. We verify that a patch does not trigger a security rule, not that it preserves the program’s intended behavior. A separate functional benchmark (for example HumanEval) would be needed to confirm no regression in general code quality.
Per-CWE weaknesses. SecFix-V3 still fails systematically on a few classes, notably insecure deserialization (CWE-502) and eval injection (CWE-095), where every evaluated instance was flagged unsafe.
7. Conclusion
A 22-billion-parameter open-weight code model, fine-tuned entirely on a single on-premise device with SFT followed by DPO over a carefully validated multi-language dataset, reaches statistical parity with Claude Opus 4.8 on security code remediation and clearly surpasses the previous frontier generation. The decisive factor was data: scaling from 502 to 4,811 validated pairs and from one to twelve languages drove every measurable improvement, while preference optimization only helped once its strength was tuned and its training signal was clean. For organizations that cannot send code to a hosted API, the result is encouraging: frontier-level security remediation is achievable in a self-hosted model an order of magnitude smaller than the cloud frontier.
Reproducibility note. All scripts, training configurations, dataset statistics, raw evaluation outputs, and bootstrap confidence-interval files are stored alongside this paper. The training pipeline is gated on an automated nine-check confirmation step that refuses to start unless the dataset passes leakage and distribution validation.
About the author
Anthony Bondu
Security Engineer
Related posts
Research
July 2, 2026
Reaching Frontier Parity in Security Code Remediation with an On-Premise 22B Model
We fine-tune Codestral-22B on 4,811 validated vulnerability fix triples using SFT + DPO in 4-bit QLoRA. Results show parity with Claude Opus 4.8 on CyberSecEval remediation and a non-significant gap on SecurityEval.
We Scanned 1,072 Vibe Coded Apps, 98% Had Security Flaws!
We crawled 65,643 URLs and scanned 1,072 Supabase backed vibe coded apps. 98 percent had security issues and 16 percent had critical flaws. Learn what is failing and what to fix first with RLS.

.png)
.png)
