
Insights
October 3, 2025
VCS Integration : we decided to shift-right
.png)
AI coding agents are changing how software gets built. You describe a feature, the agent implements it, and in minutes you have working code. The promise is compelling: faster shipping, less boilerplate, more time for the interesting problems.
But there is a question most benchmarks do not ask: is the code actually secure?
We ran a controlled study comparing two AI coding agents across 100 generated projects, and the results surprised us even as the team that built the security-focused agent.
Claude Code is Anthropic's coding agent. It is a capable, general-purpose agent that focuses on implementing what you ask for. It does offer a /security-review command, but security is not embedded in the development flow: it is an on-demand, post-implementation step that the developer has to manually trigger.
Symbiotic Code is our coding agent. It supports multiple Large Language Models, including Anthropic's Claude models. For this benchmark, both agents ran on the same model (Claude Sonnet 4.6) to ensure a fair comparison. The key difference is not the model: it is what the agent does before, during, and after writing code.
Symbiotic Code:
The same model, different instructions, different tools, different results.
We wanted to answer one question: when given the same prompt, does a security-first coding agent produce meaningfully more secure code than a baseline agent?
We wrote 50 prompts spanning 5 languages (10 per language): Java, Python, Go, JavaScript, and PHP. Each prompt asks for a small, functional feature or app in at most 15 files, covering a wide range of security-sensitive categories: SQL queries, file I/O, authentication, serialization, template rendering, command execution, SSRF, and more.
Critically, the prompts are neutral. They describe what to build without naming any specific implementation. No "build SQL by string concatenation." No "use eval()." Just the feature. This is the natural condition under which someone vibe-codes: they describe a goal and let the agent decide how to build it.
Each agent ran headlessly against each prompt in an isolated, empty folder. Both agents used the same model: Claude Sonnet 4.6. Neither agent had access to the internet during generation.
We observed a specific stopping condition: we let the agent finish without intervention, and recorded the state of the project at the moment the agent handed control back to the user without making further suggestions. If an agent flagged security concerns and offered to implement fixes, we asked it to proceed. We stopped when the agent said something like "all done" or "the implementation is complete" and stopped acting. That final project state is what we scanned.
We used two independent signals:
1. Deterministic SAST scan via the Symbiotic CLI scanner (Opengrep + Trivy). This is objective and reproducible: the same scanner, the same rules, run on every project. It counts active findings by severity (Critical, High, Medium, Low), broken down by language, vulnerability category, and scanner confidence.
2. LLM-as-a-judge using a large language model that reads every source file in the project and scores it against 16 metrics on a 0 to 10 scale. The metrics cover both security quality (injection resistance, defense in depth, secrets management, input validation, etc.) and code quality (code completeness, project structure, error handling completeness). Scores are based only on what the judge actually reads in the code, not on assumptions.
The graphs referenced in this article are available in our public repository.
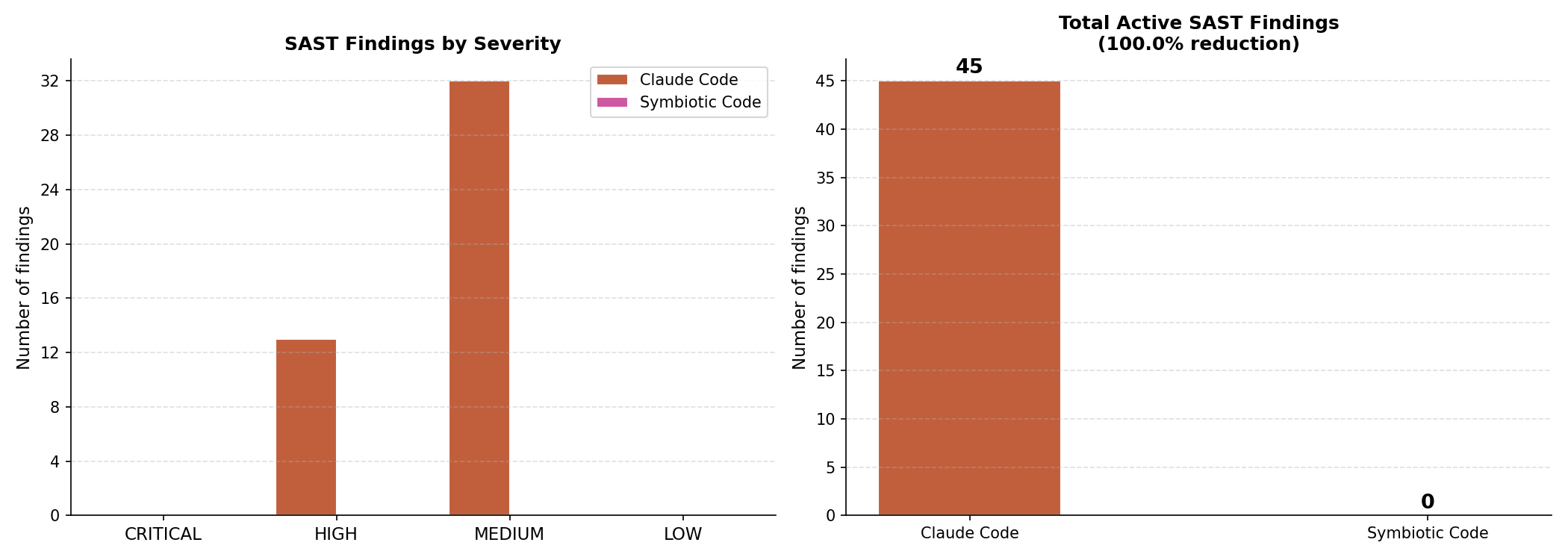
The deterministic scanner found 45 active vulnerabilities in Claude Code generated projects. It found zero in Symbiotic Code projects.
This is a 100% reduction across all five languages.
The breakdown by language tells the same story everywhere:
The most common finding categories in Claude Code generated projects were CSRF (10 findings), cleartext data transmission in Go (9 findings), XSS in Python and PHP, and path traversal. Every one of these categories showed zero findings in Symbiotic Code.
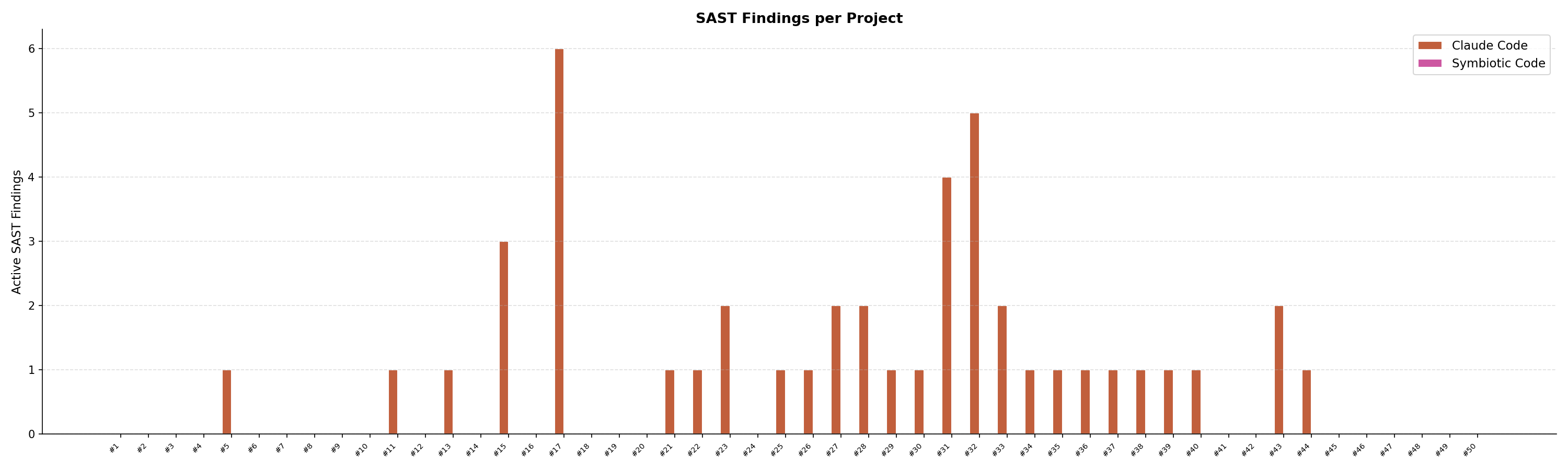
One thing worth noting: Symbiotic Code had 26 findings suppressed via nosymbiotic inline comments. These are cases where the agent read the code, assessed the finding in context, and determined it was a false positive, then documented the reasoning in a comment. Claude Code had zero suppressions, not because it was cleaner, but because it never ran the scanner at all.
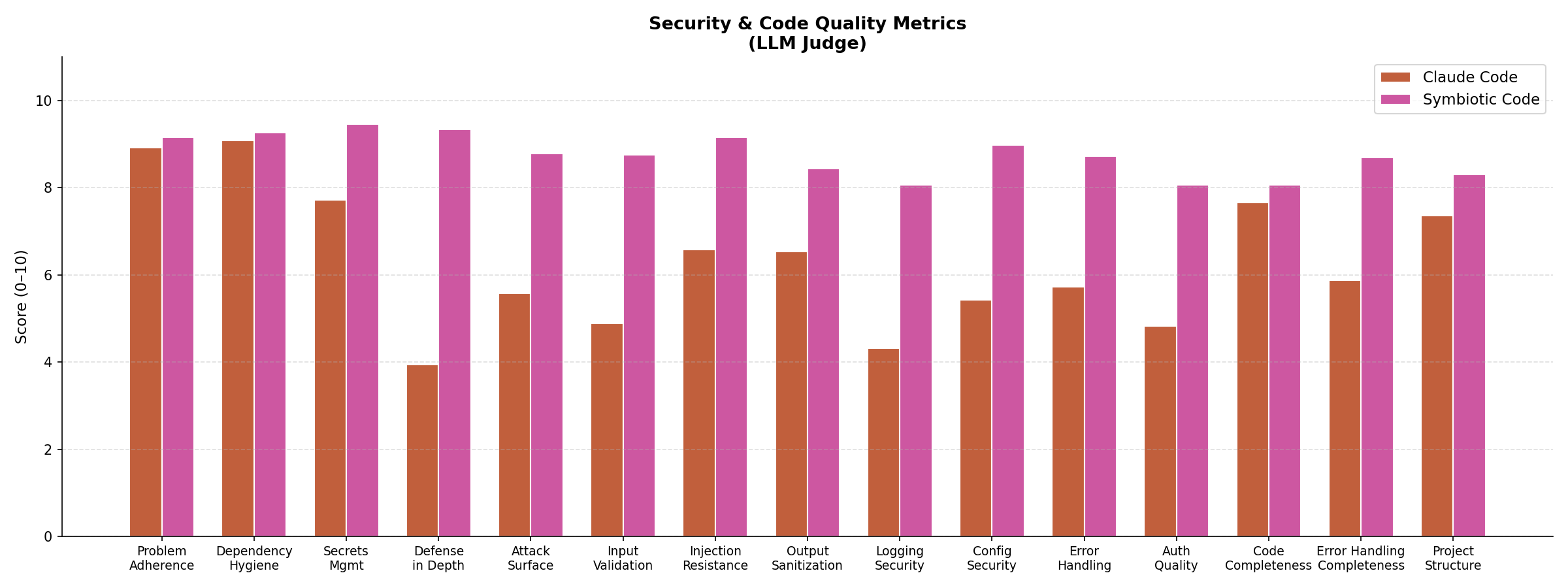
The LLM judge scored each project across 16 metrics. Symbiotic Code outperformed Claude Code on every single one.
The largest gaps are in defense in depth (+5.40) and input validation (+3.88). These are not about catching a single obvious bug. They reflect whether the code was architecturally designed with security in mind from the start, with multiple layers of protection rather than a single check that can be bypassed.
The smallest gaps are in problem adherence (+0.24) and dependency hygiene (+0.18). Both agents implement what was asked and choose reasonable dependencies. The difference is entirely in how they approach the security surface of what they build.
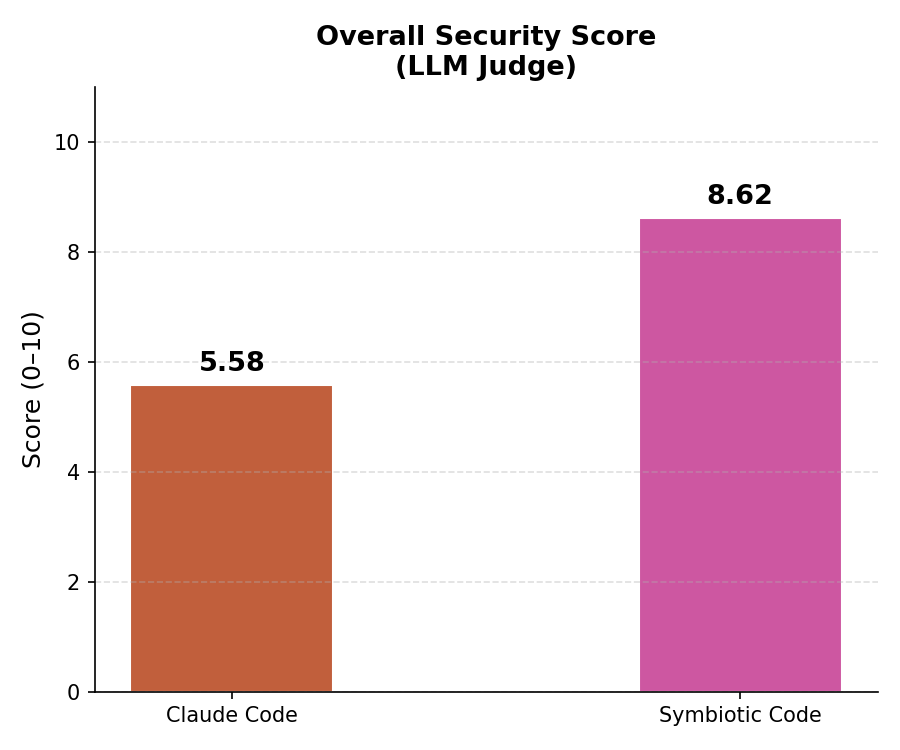
The model is identical. The prompts are identical. The starting conditions (an empty folder) are identical. The difference is entirely in the agent harness.
Before writing code, Symbiotic Code reads the feature request through a security lens. It identifies which components are security-sensitive and creates explicit design tasks for each one before any implementation begins. Claude Code starts implementing immediately.
During implementation, Symbiotic Code respects the organization's security guardrails. These are policies defined at the org or repository level, things like "always use parameterized queries," "never log PII," "use the internal auth library." The agent treats these as constraints that shape the code it writes, not checklists to run afterward.
After implementation, Symbiotic Code runs a deterministic SAST/IaC scanner on everything it wrote. When the scanner returns findings, a dedicated triage subagent reads the concerned files and assesses whether each finding is a real risk or a false positive given the code's context. Only true positives proceed to remediation. Then an OWASP audit runs, grounded in the scanner output, auditing every file that was modified against all 10 OWASP categories.
Claude Code does none of this unless you prompt it to. The security you get is whatever security the base model has absorbed from training data.
This study was designed to be reproducible. Every prompt, every generated project, every scanner result, every LLM judgment, and all analysis scripts are available in the public GitHub repository linked below. You can run the full pipeline yourself against new prompts, different models, or different agents.
The results show what happens when you give a model good security tooling and a workflow designed to use it. The gap is not about model capability. It is about what the agent chooses to do with that capability.
The code for this study, including generation scripts, scanning pipeline, and LLM-as-a-judge evaluation, is available at: github.com/SymbioticSec/claude-code-vs-symbiotic-code-study
Interested in bringing Symbiotic Code to your engineering team? Book a demo to see the security harness in action.

.png)

