In the code security world, there have always been two clear roles:
The developer writes code.
The AppSec engineer ensures that code is free of vulnerabilities.
When a vulnerability is found, the AppSec engineer reports it to the developer for remediation. This division makes sense, since AppSec teams rarely have the full development context and usually lack the development expertise to push code themselves.
The New Kid on the Block
Something fundamental has changed though.
Today, two personas write code: the developer and the Generative AI (GenAI) copilot (I'd rather say: assistant) that lives in their IDE.
But old habits die hard and our industry didn't materially change its behaviors and processes. Most organizations have kept the same workflow, simply assigning the new AI-generated code to the same accountability bucket as before: developers remain responsible for the quality and security of their AI's code.
The consensus can be summarized by the familiar mantra [footnote 1]:
AI is a copilot, not an autopilot
Now, if you think about it, this subordination most likely stems from a lack of trust towards the actual competency and judgement of our AIs. But with models seemingly being voracious learners and showing increasingly impressive reasoning capabilities, why aren't we seeing tangible and remarkable improvements? Why aren't we already at the point where we trust their judgement for code security?
A Quick Intro to Symbiotic How we Got Our Data
Not that I want to pitch you (yet), but let me explain briefly what our product does, so that you'll see where we got our insights from.
At Symbiotic, we built capabilities on top of that traditional flow to help developers at the source:
Real-time detection & remediation to automatically secure the code as it is being written
In-IDE micro-trainings for each detected vulnerability, as soon as they're created
Conversational assistant to answer questions and co-build fixes
From a security perspective, this approach works: the earlier a developer is made aware of and understands a security issue, the less likely it is to reach production. It's the shift-left argument.
But we're also shifting learning left: our 'just-in-time' learning system teaches security concepts - to humans - as soon as they need it, and specifically for what they need it.
It's a very robust learning system that proved very effective with skeptical, time-pressured learners such as developers. But more importantly in the context of this article, it gave us a baseline to compare human and AI performance in learning.
Insight Gained
After months of deployment and usage at customers', we noticed something that changed our perspective.
Developers were improving. Their AI assistants were not.
Specifically. the developers learned from the trainings, they internalized patterns and started introducing fewer vulnerabilities per kilo lines of code.
Meanwhile, their GenAIs kept making the same security mistakes, some of them basic. And there wasn't any given type of vulnerability for which you could think "at least we got rid of these" (which would have at least alleviated some of the mental burden of reviewing code).
Over time, developers began to find it tiring to remind their AI tools of the same security rules and best practices, over and over. And “Memory” features meant to retain context rarely worked when it came to security-sensitive patterns.
The problem wasn’t that AI was bad at security. It was that AI wasn’t learning security.
Why: Limitations of Existing AI Training
When people talk about “training” AI models, they usually mean fine-tuning or retrieval-augmented generation (RAG).
Both are useful, but neither helps an AI develop a lightweight, adaptable, and context-aware security memory. Fine-tuning is slow and rigid. RAG retrieves information reactively but doesn’t shape the model’s behavior.
So, we went on a quest to complement the innate learning capabilities of AIs.
Guardrails
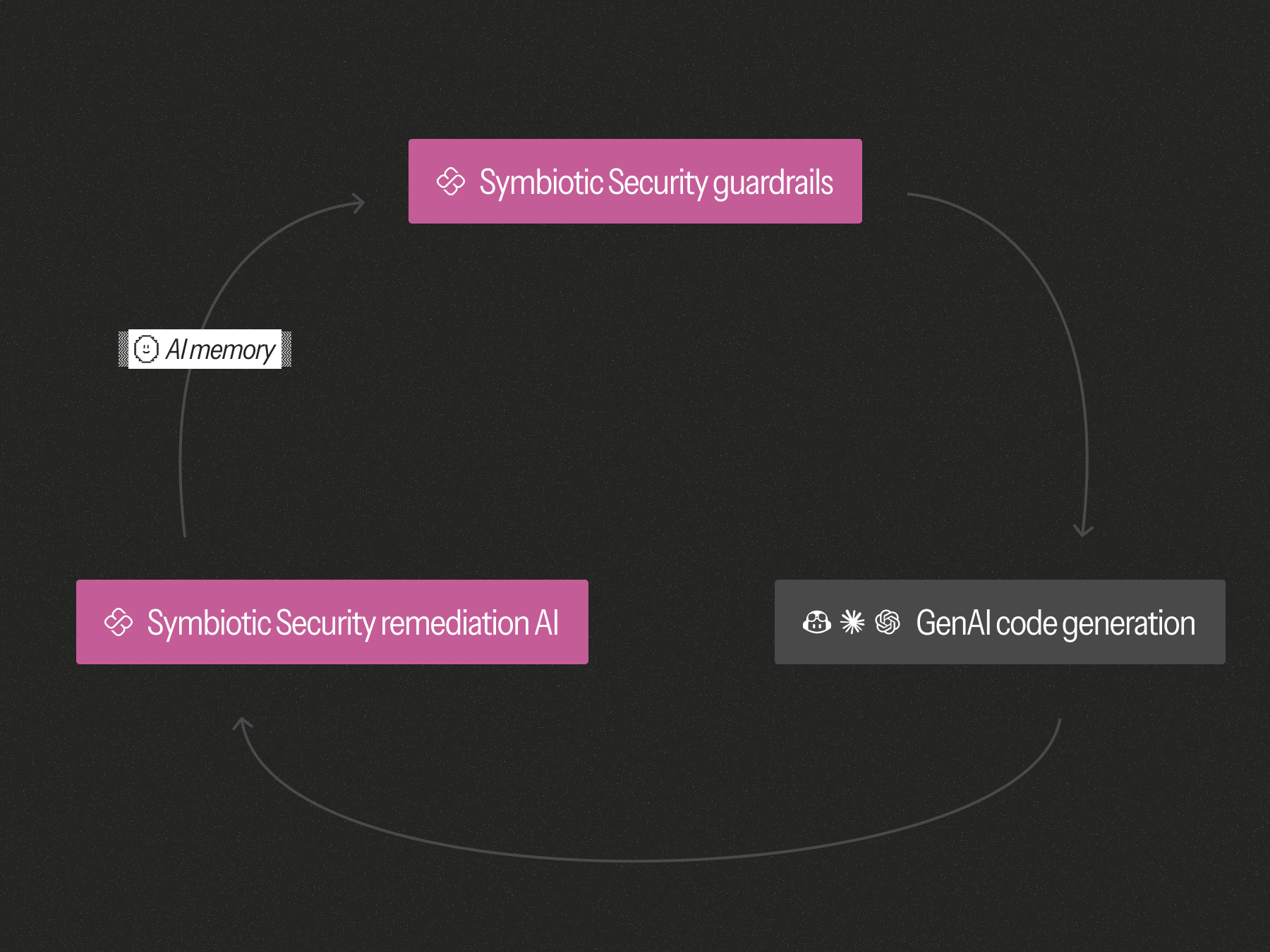
Our first step was to design guardrails: markdown pre-prompts that influence the GenAI’s behavior before code generation.
They come in two layers:
Organization-wide guardrails enforce general policies, such as “Use HashiCorp Vault for secrets.”
Per-repository guardrails adapt to local context, like language, framework, and stack. Because the way you sanitize database inputs in Node.js is not the same as in Django. Guardrails let the AI know that before it writes a single line.
Now the thinking here was that if we could make our guardrails "learn" security, then it would in turn progressively improve the AI output. The AIs wouldn't learn, per se, but our progressive accumulation of knowledge would eventually translate into better security output from the AI.
I call this learning.
Make Memories
Most organizations already have security policies, but they live at compliance level and never or rarely go as deep as to provide code-level, project-specific recommendations.
We had to change that to create guardrails that were truly specific, meaningful, and that - because they'd live in the same dimension - could "learn" from code.
We used the real remediations our system performs with developers for that. Specifically: every time a vulnerability is fixed, the secure pattern is recorded and turned into a reusable rule. A memory of good behavior. Learned guardrails.
These memories evolve with the codebase. Over time, they become the AI’s lived experience of security and grow into a far-reaching corpus that significantly change our customers' AI behavior.
Outcome: Adaptable Security-by-design
All in all, and as the name suggest, we're pretty big believers in the necessity to establish a symbiotic relationship between AIs and developers. Accordingly, we believe both need to learn, but our experience shows that they learn in different ways.
Recognizing this pattern allowed us to build a pragmatic system to make our customers' GenAIs safer over time and to accelerate their secure-by-design ambitions.
I know... not familiar at all
About the author
Edouard Viot
CTO - Chief Technology Officer
With over 16 years of experience across the cybersecurity spectrum and 6 years in executive roles, Édouard is a seasoned expert in the field. He has led the design and development of innovative products in Application Security (GitGuardian), Web Application Firewalls (DenyAll), and Endpoint Detection and Response (Stormshield). A hacker at heart, Édouard is also a respected team leader, known for his ability to inspire and guide high-performance teams to success.
Related posts
Insights
June 25, 2025
Exploring the Study: Security Degradation in Iterative AI Code Generation
The study “Security Degradation in Iterative AI Code Generation” made clear that more iteration on code using LLMs leads to more security vulnerabilities.
We launched Symbiotic Security with a vision of the future where development teams are seamlessly supported by security at every step, with real-time guidance and learning integrated into their workflow.




.png)

